
 JazzCharles
a3f115f716
Update README.md
JazzCharles
a3f115f716
Update README.md
|
1 year ago | |
|---|---|---|
| configs | 1 year ago | |
| convert_dataset | 1 year ago | |
| datasets | 1 year ago | |
| figs | 1 year ago | |
| imagenet_info | 1 year ago | |
| models | 1 year ago | |
| segmentation | 1 year ago | |
| tools | 1 year ago | |
| utils | 1 year ago | |
| .gitignore | 1 year ago | |
| LICENSE | 1 year ago | |
| README.md | 1 year ago | |
| main_pretrain.py | 1 year ago | |
| main_seg.py | 1 year ago | |
| requirements.txt | 1 year ago | |
| setup.cfg | 1 year ago |
README.md
Learning Open-Vocabulary Semantic Segmentation Models From Natural Language Supervision
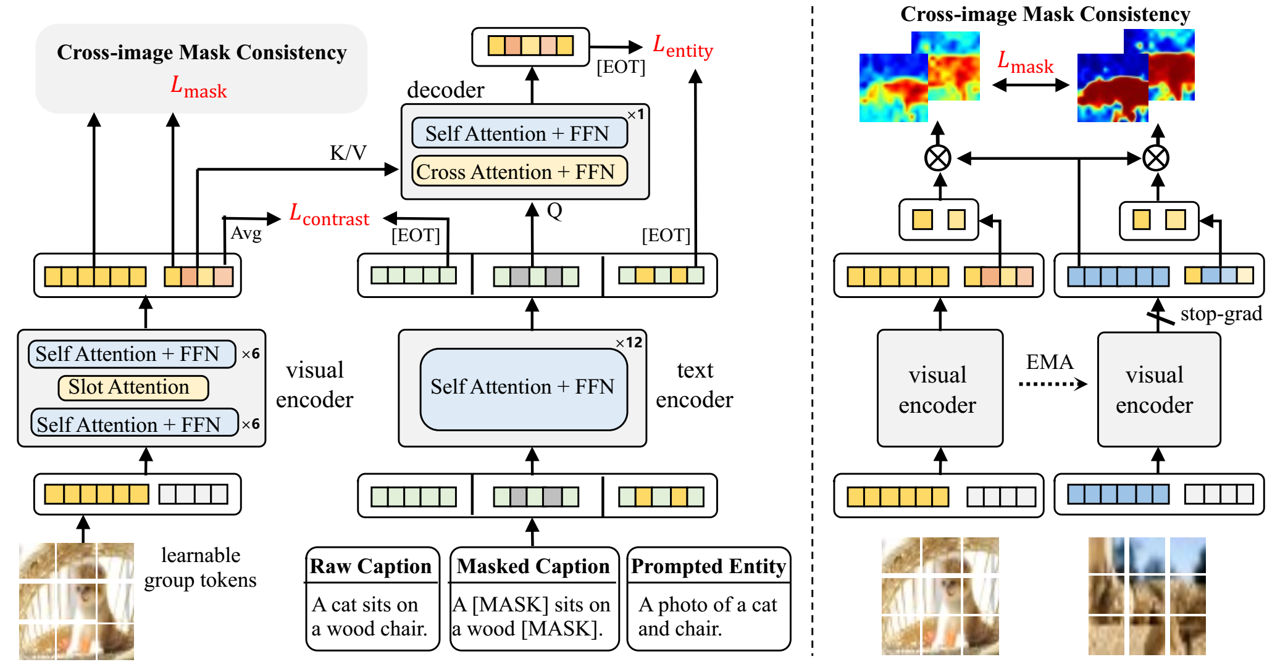
This repository is the official implementation of Learning Open-Vocabulary Semantic Segmentation Models From Natural Language Supervision at CVPR 2023. Our transformer-based model, termed as OVSegmentor, is pre-trained on image-text pairs without using any mask annotations. After training, it can segment objects of arbitrary categories via zero-shot transfer.
Requirements
- Python 3.9
- torch=1.11.0+cu113
- torchvision=0.14.1
- apex=0.1
- mmcv-full=1.3.14
- mmsegmentation=0.18.0
- clip=1.0
We recommand installing apex with cuda and c++ extensions
To install the other requirements:
pip install -r requirements.txt
Prepare datasets
For training, we construct CC4M by filtering CC12M with a total number of 100 frequently appearred entities. The researchers are encouraged to prepare CC12M dataset from the source or using img2dataset. Note that, some url links may not be available any longer. The file structure should follow:
CC12M
├── 000002a0c848e78c7b9d53584e2d36ab0ac14785.jpg
├── 000002ca5e5eab763d95fa8ac0df7a11f24519e5.jpg
├── 00000440ca9fe337152041e26c37f619ec4c55b2.jpg
...
We provide the meta-file for CC4M at here for data loading. One may also try different image-caption datasets (e.g. YFCC, RedCaps) by providing the images and the corresponding meta-file. The meta-file is a json file containing each filename and its caption in a single line.
{"filename": "000002ca5e5eab763d95fa8ac0df7a11f24519e5.jpg", "caption": "A man's hand holds an orange pencil on white"}
{"filename": "000009b46e38a28790f481f36366c781e03e4bbd.jpg", "caption": "Cooking is chemistry, except you CAN lick the spoon!"}
...
For evaluation, please follow the official websites to prepare PASCAL VOC, PASCAL Context, COCO converted to semantic seg format following GroupViT, and ADE20K. Remember to change the image dirs in segmentation/configs/base/datasets/*.py.
To enable zero-shot classification evaluation, please prepare the validation set of ImageNet with its corresponding meta-file.
Other preparations
- The visual encoder is initialised with DINO. Edit the checkpoint path in the config file.
- Pre-trained BERT model and nltk_data should be downloaded automatically.
Training
To train the model(s) in the paper, we separate the training process as a two-stage pipeline. The first stage is a 30-epoch training with image-caption contrastive loss and masked entity completion loss, and the second-stage 10-epoch training further adds the cross-image mask consistency loss.
For the first stage training on a single node with 8 A100 (80G) GPUs, we recommand to use slurm script to enable training:
cd OVSegmentor
./tools/run_slurm.sh
Or simply use torch.distributed.launch as:
./tools/run.sh
After that, please specify the checkpoint path from the 1st stage training in the config file used in the 2nd stage training (e.g. configs/ovsegmentor/ovsegmentor_pretrain_vit_bert_stage2.yml). During cross-image sampling, we sample another image that share the same entity with the current image. This is achieved by (1) identifying the visual entity for the image. (2) Perform sampling over the valid candidates. We offer the pre-processed class_label.json and sample_list.json.
We also provide our pre-trained 1st stage checkpoint from here.
Then, perform the second stage training.
./tools/run_slurm_stage2.sh
We adjust a few hyperparameters in 2nd stage to stablize the training process.
Evaluation
To evaluate the model on PASCAL VOC, please specify the checkpoint path in tools/test_voc12.sh, and run:
./tools/test_voc12.sh
For PASCAL Context, COCO Object, and ADE20K, please refer to tools/.
The performance may vary 3%~4% due to different cross-image sampling.
Model Zoo
The pre-trained models can be downloaded from here:
| Model name | Visual enc | Text enc | Group tokens | PASCAL VOC | PASCAL Context | COCO Object | ADE20K | Checkpoint |
|---|---|---|---|---|---|---|---|---|
| OVSegmentor | ViT-B | BERT-Base | 8 | 53.8 | 20.4 | 25.1 | 5.6 | download |
| OVSegmentor | ViT-S | Roberta-Base | 8 | 44.5 | 18.3 | 19.0 | 4.3 | download |
| OVSegmentor | ViT-B | BERT-Base | 16 | Todo | Todo | Todo | Todo | Todo |
Citation
If this work is helpful for your research, please consider citing us.
@inproceedings{xu2023learning,
title={Learning open-vocabulary semantic segmentation models from natural language supervision},
author={Xu, Jilan and Hou, Junlin and Zhang, Yuejie and Feng, Rui and Wang, Yi and Qiao, Yu and Xie, Weidi},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={2935--2944},
year={2023}
}
Acknowledgements
This project is built upon GroupViT. Thanks to the contributors of the great codebase.